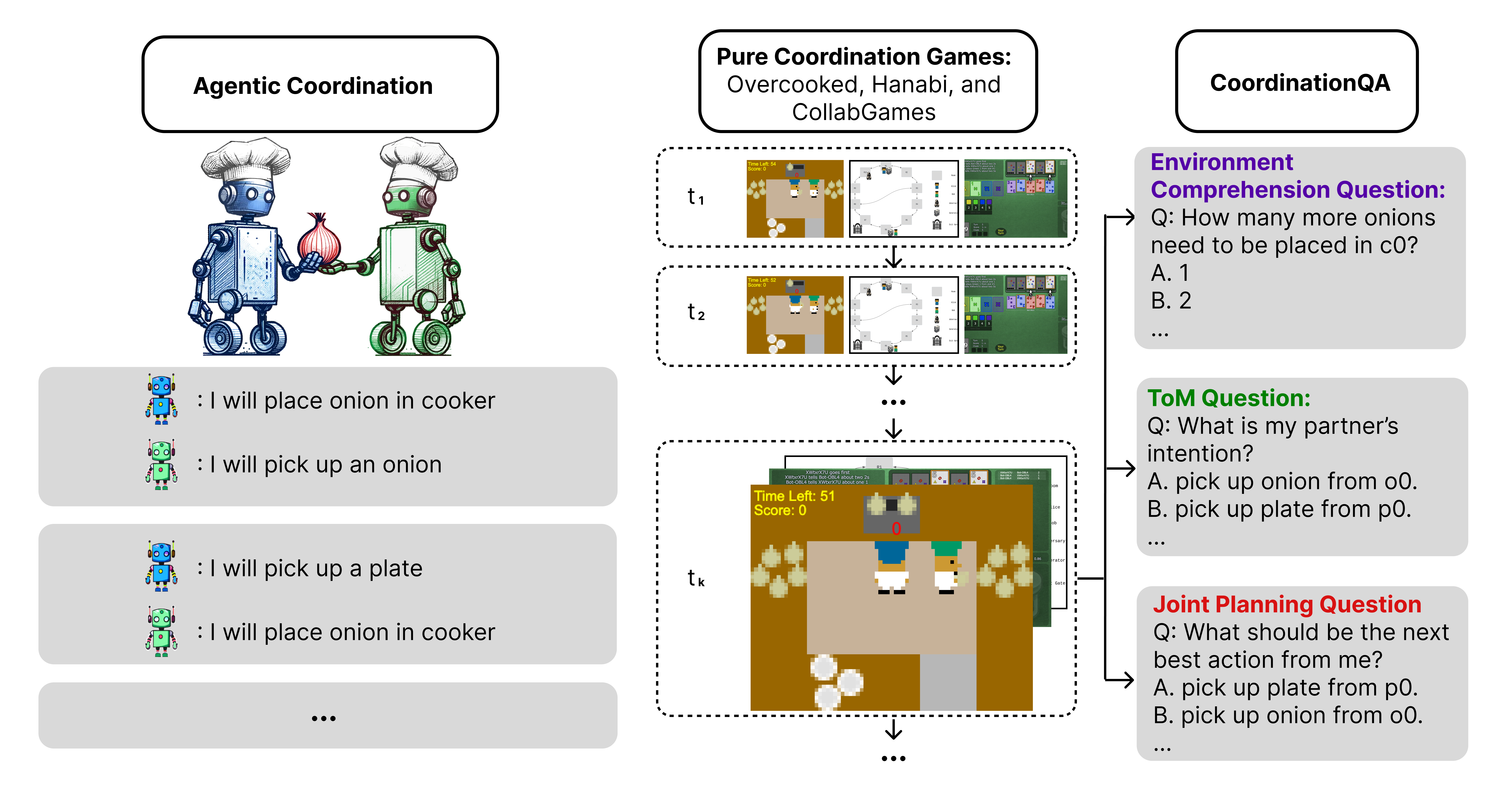
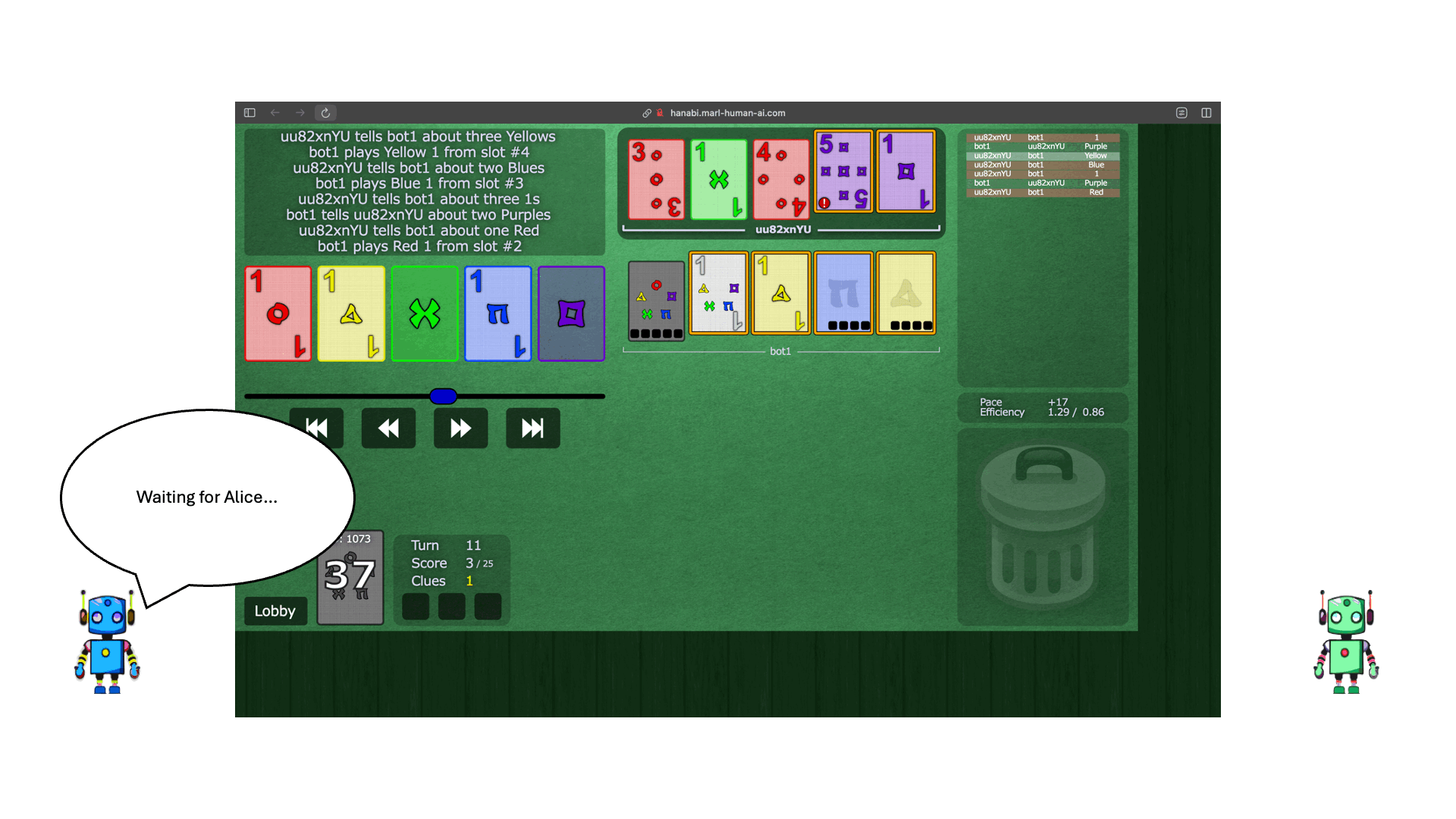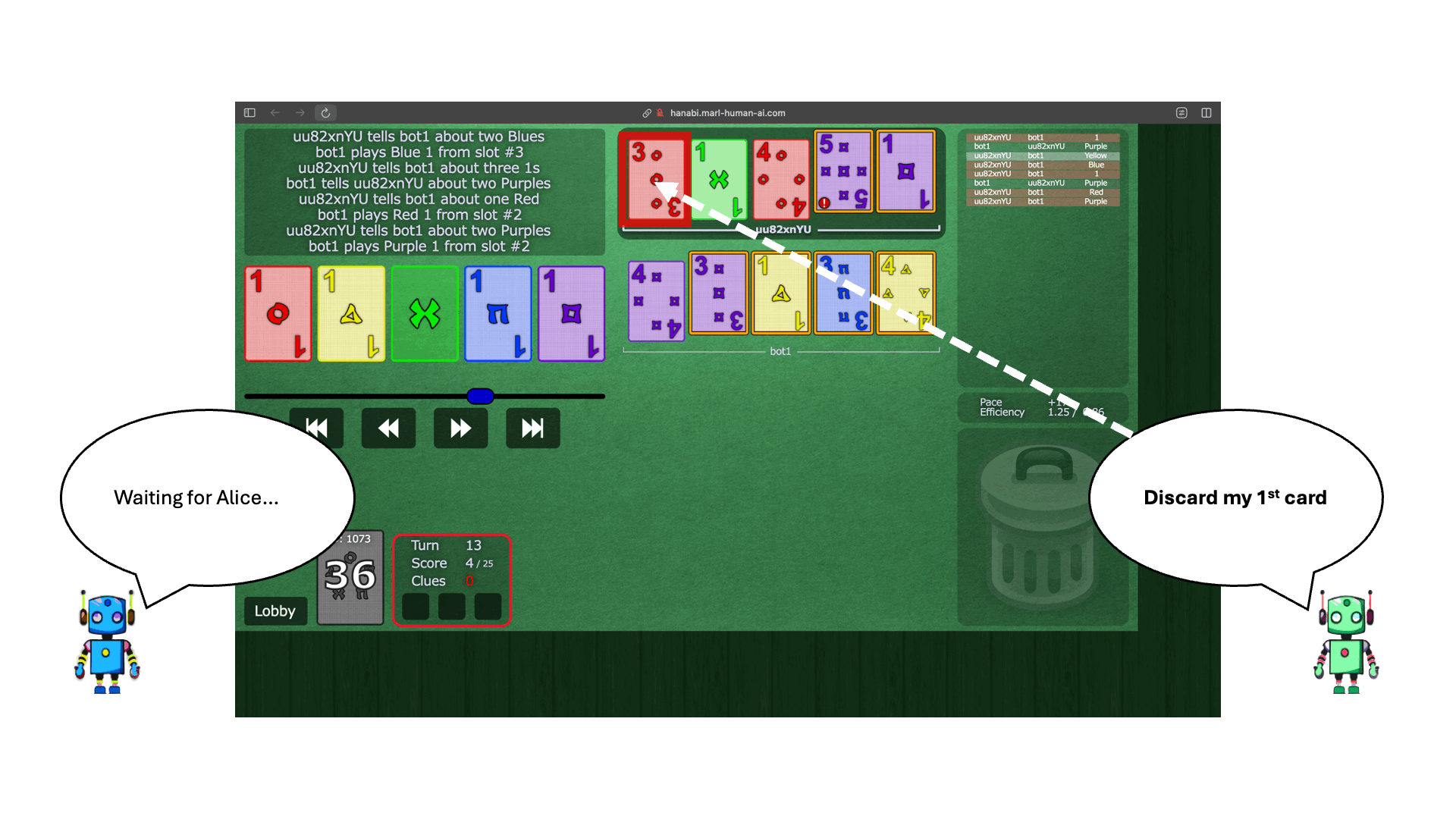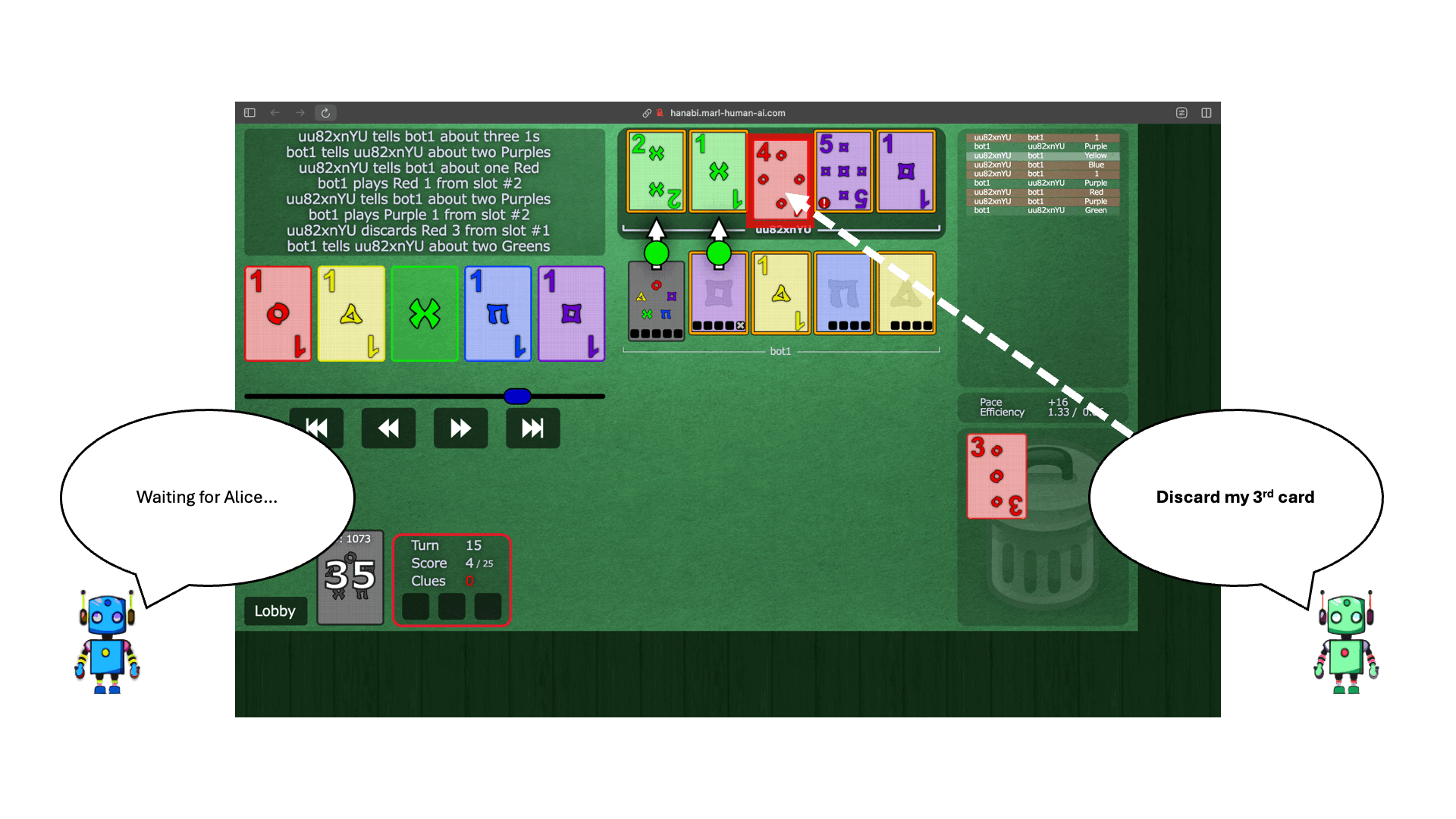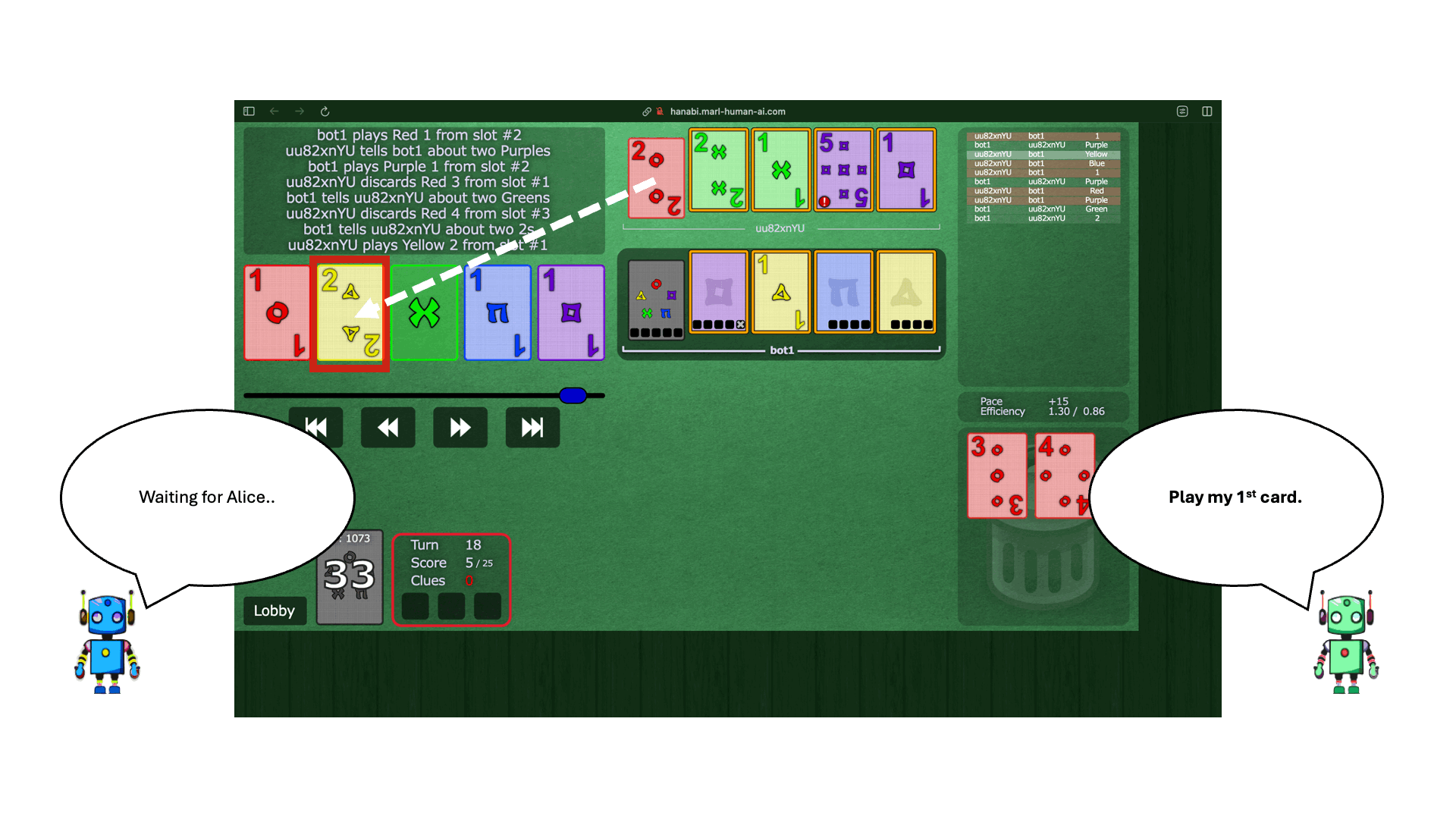
.png)
@misc{agashe2023evaluating,
title={Evaluating Multi-Agent Coordination Abilities in Large Language Models},
author={Saaket Agashe and Yue Fan and Xin Eric Wang},
year={2023},
eprint={2310.03903},
archivePrefix={arXiv},
primaryClass={cs.CL}
}