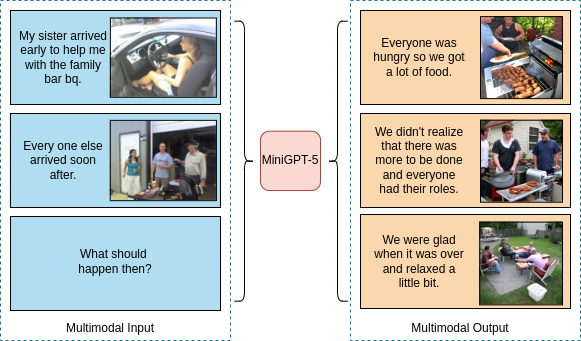
Figure 1. MiniGPT-5 is a unified model for interleaved vision-and-language comprehension and generation. Besides the original multimodal comprehension and text generation abilities, MiniGPT-5 can provide appropriate, coherent multimodal outputs.
Large Language Models (LLMs) have garnered significant attention for their advancements in natural language processing, demonstrating unparalleled prowess in text comprehension and generation. Yet, the simultaneous generation of images with coherent textual narratives remains an evolving frontier. In response, we introduce an innovative interleaved vision-and-language generation technique anchored by the concept of "generative vokens", acting as the bridge for harmonized image-text outputs. Our approach is characterized by a distinctive two-staged training strategy focusing on description-free multimodal generation, where the training requires no comprehensive descriptions of images. To bolster model integrity, classifier-free guidance is incorporated, enhancing the effectiveness of vokens on image generation. Our model, MiniGPT-5, exhibits substantial improvement over the baseline Divter model on the MMDialog dataset and consistently delivers superior or comparable multimodal outputs in human evaluations on the VIST dataset, highlighting its efficacy across diverse benchmarks.
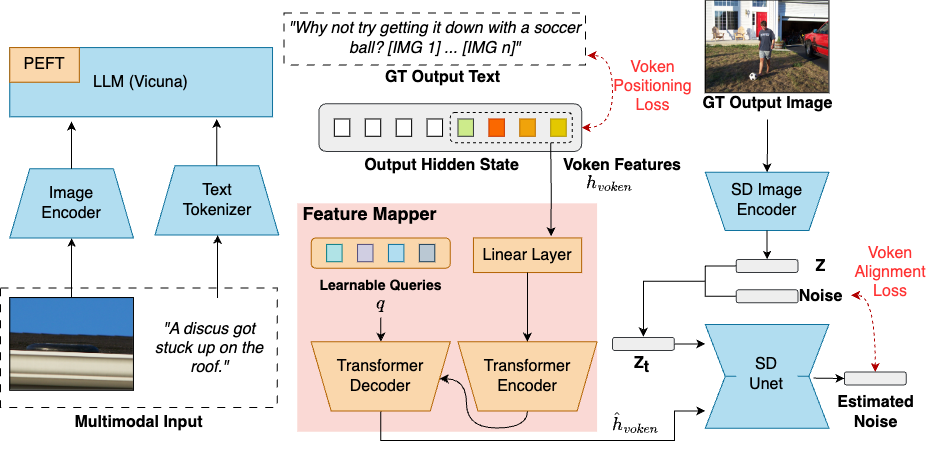
Figure 2. MiniGPT-5 pipeline.
Qualitative examples from MiniGPT-5 and baselines on the CC3M, VIST, and MMDialog datasets. From the comparisons, we can find the MiniGPT-5 and SD 2 have similar results on single-image generation. When we evaluate with multi-step multimodal prompts, MiniGPT-5 can produce more coherent and high-quality images.
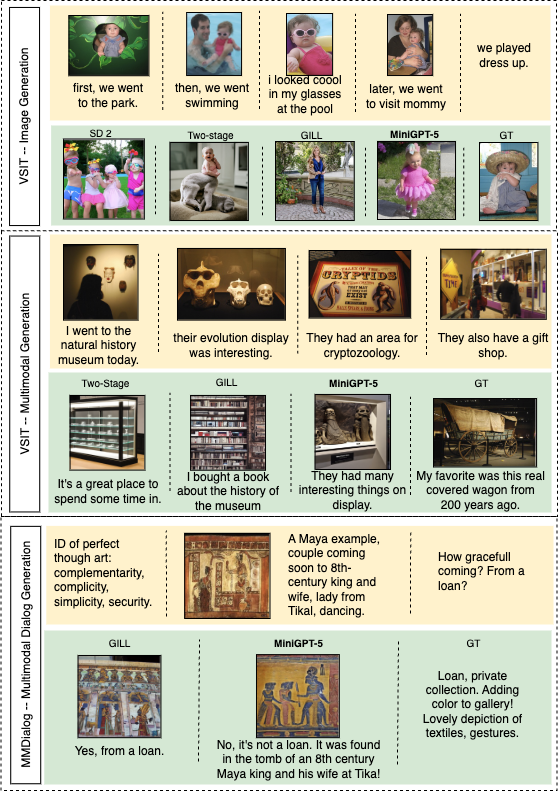
Figure 3. Comparison with other baselines.
@misc{zheng2023minigpt5,
title={MiniGPT-5: Interleaved Vision-and-Language Generation via Generative Vokens},
author={Kaizhi Zheng and Xuehai He and Xin Eric Wang},
year={2023},
journal={arXiv preprint arXiv:2310.02239}
}